Análisis de las bebidas de Starbucks
Contribución a TidyTuesday, semana 52
Este fin de año estuvo bastante movido, entre la organización del VI Encuentro de Investigadores en Desarrollo, Aprendizaje y Educación y la escritura de ¡dos! papers. Y sin tener en cuenta la pandemia.
Venía con ganas de hacer algo para #TidyTuesday, pero no me motivaron mucho las últimas propuestas. No me malinterpreten, amo a las Spice Girls y las arañas me resultan simpáticas (aunque no podría decir que me interesa mucho el cricket), pero los tipos de datos que traían no me resultaban particularmente convocantes. Si bien este proyecto apunta a trabajar herramientas de visualización, lo que más necesito en este momento es mejorar mis habilidades estadísticas.
Por eso elegí esta semana: datos sobre las bebidas de Starbucks. El dataset tiene mucha información numérica que me va a permitir reproducir un análisis estadístico básico. Empecemos primero por importar y organizar un poco los datos.
tuesdata <- tidytuesdayR::tt_load('2021-12-21')## --- Compiling #TidyTuesday Information for 2021-12-21 ----## --- There is 1 file available ---## --- Starting Download ---##
## Downloading file 1 of 1: `starbucks.csv`## --- Download complete ---starbucks <- tuesdata$starbucks
starbucks$product_name <- as.factor(starbucks$product_name)
starbucks$size <- as.factor(starbucks$size)
starbucks$milk <- as.factor(starbucks$milk)
starbucks$whip <- as.factor(starbucks$whip)
starbucks$trans_fat_g <- as.numeric(starbucks$trans_fat_g)
starbucks$fiber_g <- as.numeric(starbucks$fiber_g)Análisis descriptivo
Para entender un poco más cómo están compuestas estas bebidas, vamos a realizar un análisis descriptivo. Tenemos dos medidas de tamaño (size y serve_size_m_l), calorías, grasas totales (grasas saturadas y grasas trans), gramos de colesterol, gramos de sodio, carbohidratos totales, gramos de fibra, gramos de azúcar y gramos de cafeína.
Lo primero que vamos a hacer es ver cómo se distribuyen las bebidas según la cantidad de esos ingredientes. Sin embargo, me encontré con el problema de que los distintos elementos aparecen, incluso dentro de su distribución, con valores absolutos muy diferentes. Esto hace que no se distingan con claridad si los presento todos en un mismo gráfico. Voy a mantener entonces la separación por tamaños, pero solo voy a trabajar con los tamaños estándares (short, tall, venti, grande).
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
## ✔ ggplot2 3.4.0 ✔ purrr 0.3.5
## ✔ tibble 3.1.8 ✔ dplyr 1.0.10
## ✔ tidyr 1.2.1 ✔ stringr 1.4.1
## ✔ readr 2.1.3 ✔ forcats 0.5.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()starbucks_longer <- starbucks %>%
mutate(caffeine_g = caffeine_mg*100,
cholesterol_g = cholesterol_mg*100,
sodium_g = sodium_mg*100) %>%
select(-c(caffeine_mg, cholesterol_mg, sodium_mg)) %>%
pivot_longer(cols = c(5:15),
names_to = "character",
values_to = "n")
starbucks_longer$size <- factor(starbucks_longer$size, levels = c("short", "tall", "grande", "venti"))
starbucks_longer %>%
filter(character %in% c("calories", "total_fat_g", "sodium_g", "cholesterol_g", "fiber_g", "sugar_g", "caffeine_g")) %>%
filter(size %in% c("short", "tall", "venti", "grande")) %>%
ggplot()+
geom_density(mapping = aes(n, color = size))+
facet_wrap(~character, scales = "free")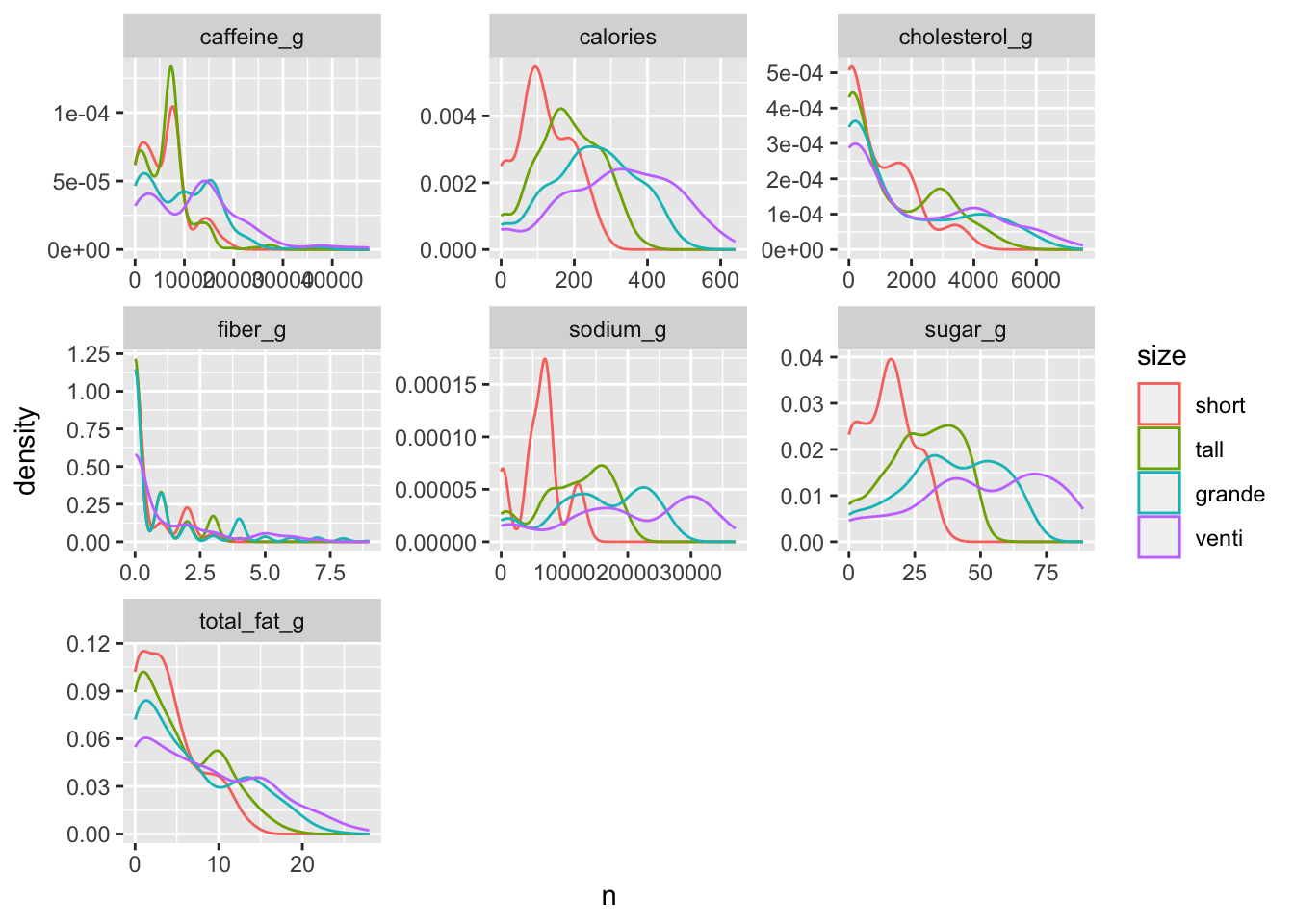
En principio, se puede ver que a grandes rasgos los gráficos siguen el patrón lógico: los tamaños más grandes tienen distribuciones más aplanadas, mientras que los tamaños más chicos tienen picos más pronunciados. Me llama particularmente la atención el gráfico de cafeína: tanto el tamaño “short” como el “tall” tienen un pico muy similar (¿mucha cafeína para un tamaño pequeño o poca cafeína para un tamaño más grande?). Es posible, de todos modos, que no todos los tipos de bebidas tengan los cuatro tamaños, y que esto incorpore sesgos en los gráficos. Lo veremos más adelante.
starbucks_longer %>%
filter(character %in% c("calories", "total_fat_g", "sodium_g", "cholesterol_g", "fiber_g", "sugar_g", "caffeine_g")) %>%
filter(size %in% c("short", "tall", "venti", "grande")) %>%
ggplot()+
geom_boxplot(mapping = aes(x = size, y = n, fill = size))+
facet_wrap(~character, scales = "free")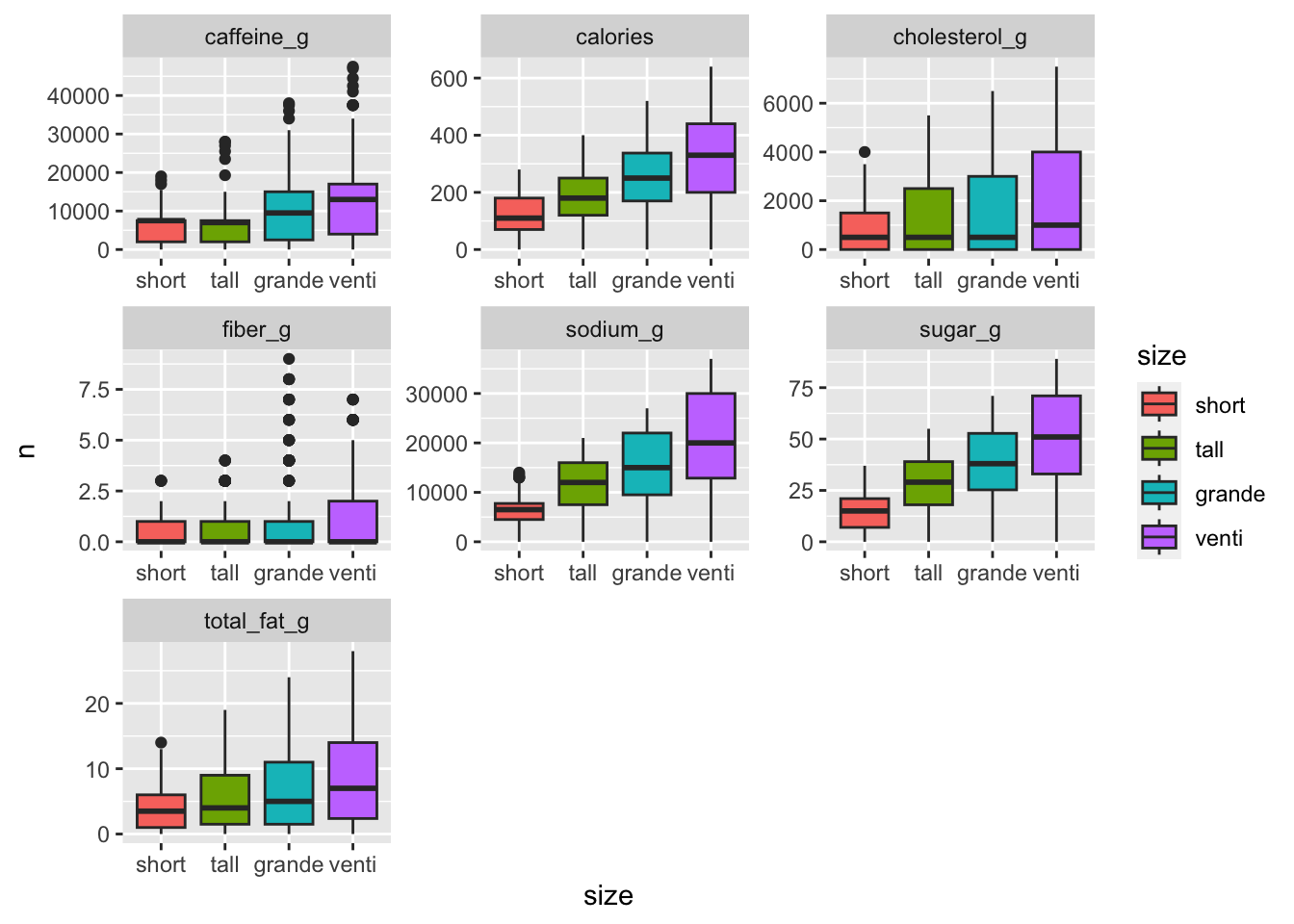
El boxplot muestra con más claridad la diferencia entre los tamaños, que de todos modos sigue mostrando similitudes en los primeros dos tamaños para la cantidad de cafeína como de fibra. Una buena pregunta para más adelante es: ¿hay diferencias estadísticamente significativas entre la cantidad de cafeína en las bebidas de los primeros dos tamaños?
Ahora, ¿cuáles son las bebidas con más cantidad de cada elemento? Para poder comparar, vamos a quedarnos con las versiones más pequeñas (“short”), sin tener en cuenta otras características:
library(gt)
library(gtExtras)
starbucks %>%
filter(size == "short") %>%
arrange(desc(caffeine_mg)) %>%
select(product_name, caffeine_mg) %>%
unique() %>%
slice_head(n =10) %>%
gt() %>%
tab_options(
column_labels.text_transform = "Nombre del producto"
) %>%
tab_header(title = "Los 10 productos con más cafeína") %>%
gt_theme_nytimes() %>%
tab_source_note(source_note = "Source: Starbucks Coffee Company | Made by @_msquiroga for #TidyTuesday") %>%
cols_align("left")| Los 10 productos con más cafeína | |
| product_name | caffeine_mg |
|---|---|
| Clover Brewed Coffee - Dark Roast | 190 |
| brewed coffee - True North Blend Blonde roast | 180 |
| Clover Brewed Coffee - Medium Roast | 170 |
| brewed coffee - medium roast | 155 |
| Clover Brewed Coffee - Light Roast | 155 |
| Latte Macchiato | 150 |
| brewed coffee - dark roast | 130 |
| Flat White | 130 |
| Caffè Mocha | 90 |
| Caffè Misto | 75 |
| Source: Starbucks Coffee Company | Made by @_msquiroga for #TidyTuesday | |
Ya saben, amigos: si necesitan una ayudita para empezar su día, pueden pasar por su Starbucks más cercano y pedir un Clover Brewed Coffee - Dark Roast (si es que existe en sus países, claro: en el mío me parece que no).
Regresión
Empecé este post planteando que quería practicar mis habilidades estadísticas, pero ya no estoy tan segura de que este dataset me dé muchas oportunidades para hacer grandes operaciones. Por el momento, me voy a quedar con esta pregunta: ¿qué aspecto de la composición de las bebidas aporta significativamente más a la cantidad de grasas totales? Por supuesto que es una respuesta que se puede conseguir desde un punto de vista nutricional: la presencia de leche y de crema, junto con el tamaño de la bebida, deberían ser los tres predictores más significativos. Pero veamos si la estadística nos acompaña.
starbucks <- starbucks %>%
filter(!size %in% c("1 scoop", "1 shot"))
fat_reg <- lm(total_fat_g ~ size + milk + whip + serv_size_m_l + calories + cholesterol_mg + sodium_mg + fiber_g + sugar_g + caffeine_mg, data = starbucks)
summary(fat_reg)##
## Call:
## lm(formula = total_fat_g ~ size + milk + whip + serv_size_m_l +
## calories + cholesterol_mg + sodium_mg + fiber_g + sugar_g +
## caffeine_mg, data = starbucks)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5403 -0.5246 0.0487 0.5103 7.6863
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.2538835 0.4009213 -0.633 0.5267
## sizegrande -1.2414507 0.6557588 -1.893 0.0586 .
## sizequad -0.7248447 0.5507526 -1.316 0.1884
## sizeshort -0.2524751 0.4828904 -0.523 0.6012
## sizesolo 0.4126085 0.5473979 0.754 0.4511
## sizetall -0.5817991 0.5569494 -1.045 0.2964
## sizetrenta -1.5889205 1.0794471 -1.472 0.1413
## sizetriple -0.3613976 0.5473937 -0.660 0.5093
## sizeventi -1.8653208 0.8295612 -2.249 0.0247 *
## milk1 -2.5098877 0.1339820 -18.733 < 2e-16 ***
## milk2 -1.5945736 0.1510997 -10.553 < 2e-16 ***
## milk3 -0.9801896 0.1475690 -6.642 4.81e-11 ***
## milk4 0.9084118 0.1445475 6.285 4.70e-10 ***
## milk5 -0.6896911 0.1582705 -4.358 1.43e-05 ***
## whip1 1.8390692 0.1669839 11.013 < 2e-16 ***
## serv_size_m_l 0.0021254 0.0011338 1.875 0.0611 .
## calories 0.0688260 0.0013809 49.842 < 2e-16 ***
## cholesterol_mg 0.0416803 0.0064425 6.470 1.46e-10 ***
## sodium_mg 0.0047823 0.0007800 6.131 1.20e-09 ***
## fiber_g -0.5514295 0.0284809 -19.361 < 2e-16 ***
## sugar_g -0.2720957 0.0062719 -43.383 < 2e-16 ***
## caffeine_mg -0.0003979 0.0004756 -0.837 0.4029
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.022 on 1122 degrees of freedom
## Multiple R-squared: 0.9712, Adjusted R-squared: 0.9707
## F-statistic: 1801 on 21 and 1122 DF, p-value: < 2.2e-16Lo primero que miro, siempre, es que el modelo sea significativo: eso lo podemos ver con el p-value que aparece al final del resumen. Efectivamente, el modelo pareciera ser significativo; en otras palabras, la descripción de la situación que planteamos se ve acompañada por los datos. Además, el $R^2$ es muy alto.
Ahora, miramos las variables. El tamaño solo resultó ser un predictor significativo en el tamaño más grande, “venti”. Esto me llama poderosamente la atención, porque había predicho que a medida que aumentara el tamaño, la cantidad de grasas totales también aumentaría, pero es posible que al controlar por las demás variables, el tamaño ya no juegue un rol importante (¿tal vez porque cambia la composición de la bebida? ¿porque todo tiene mucha grasa siempre?).
La presencia de leche y de crema fue, como había predicho, un predictor significativo en todos los casos. Esto por supuesto que es lo lógico desde el punto de vista nutricional. Lo mismo ocurre con la cantidad de calorías: hasta donde tengo entendido, las calorías son una medida de energía producida por, justamente, grasas, proteínas y carbohidratos. Por lo tanto, si bien es lógico que haya resultado un predictor significativo, no debería haber aparecido en el modelo desde el punto de vista de la teoría que lo fundamenta. El colesterol también fue un predictor significativo, lo cual es lógico porque es un tipo de grasa.
Lo que me llama la atención es que el sodio, la fibra y el azúcar hayan sido también predictores estadísticamente significativos. Nuevamente, mi conocimiento básico de nutrición me dice que estos elementos no deberían aportar a la cantidad de grasas totales, pero es posible que los ingredientes que aportan estos elementos también contengan altos grados de grasas. Es fundamental, entonces, conocer a fondo los elementos con los que trabajamos a la hora de plantear un modelo estadístico.
Por último, podemos analizar los residuos del modelo, para tener un panorama más claro.
library(performance)
performance::check_model(fat_reg)## Variable `Component` is not in your data frame :/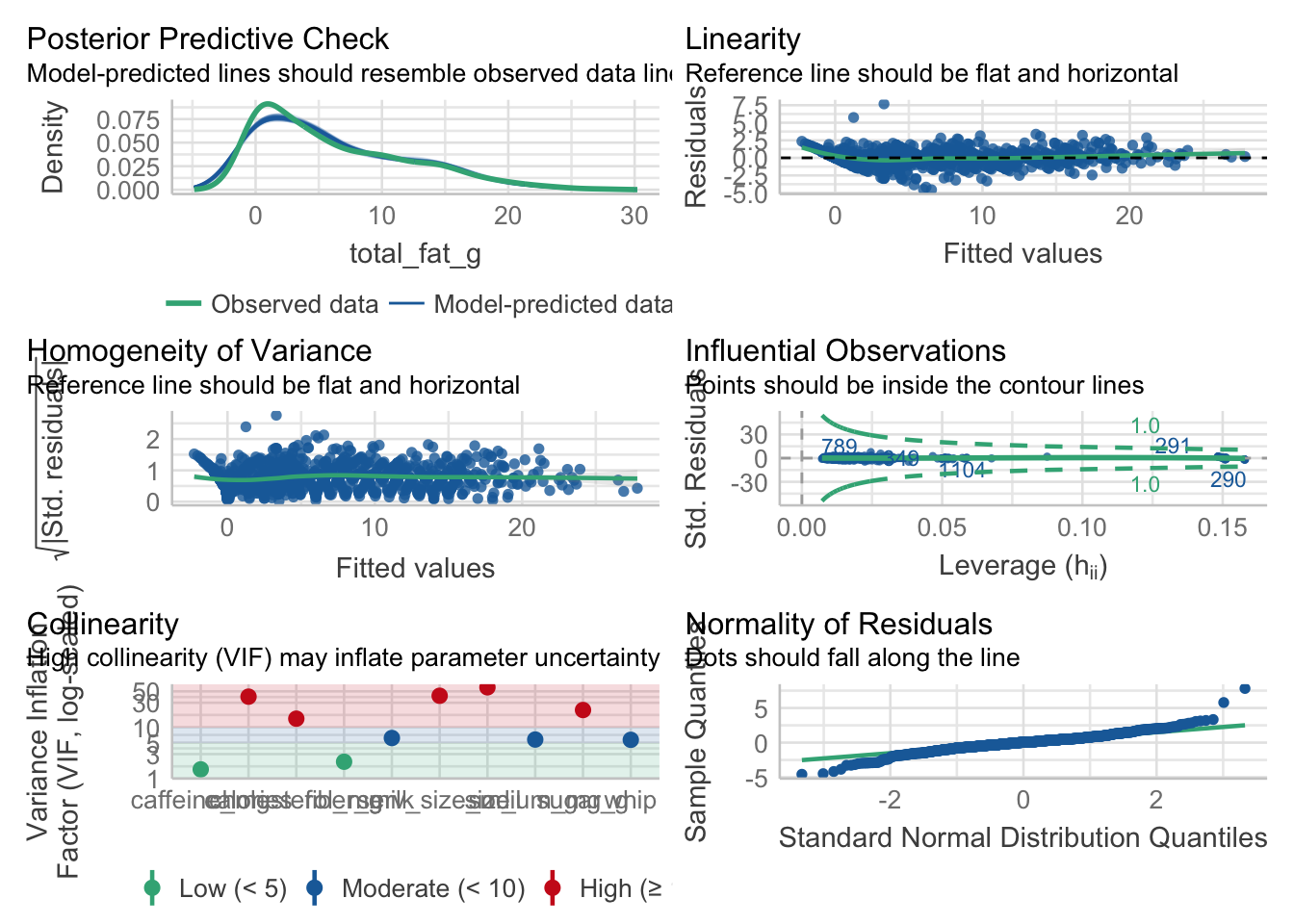
El análisis de los residuos muestra varias de las cosas mencionadas anteriormente: por ejemplo, el alto grado de colinealidad entre varios de los ingredientes. La linealidad y la homogeneidad de la varianza tienen claramente formas muy extrañas, y me pregunto si tendrá que ver con los distintos tamaños, que plantean distintas composiciones de ingredientes a partir de las mismas fórmulas. Creo que una metodología más adecuada sería correr distintos modelos para cada tamaño, para poder comparar entre bebidas (es decir, entre recetas).
En fin, el análisis de los residuos muestra, como ya sabíamos, que si bien a priori el resumen del modelo dio resultados aparentemente significativos, el análisis de los residuos muestra que hay algunas cuestiones que se escapan y que este modelo no sería el más apropiado para este panorama. Se podría continuar este análisis, como mencioné antes, corriendo distintos modelos por cada tamaño, planteando correlaciones entre los ingredientes para detectar colinealidades problemáticas. Pero con esto fue suficiente por hoy. ¡Gracias por leer!
Macarena Quiroga
Lingüista/Becaria doctoral
Investigo la adquisición del lenguaje. Estudio estadística y ciencia de datos con R/Rstudio. Si te gusta lo que hago, podés invitarme un cafecito desde Argentina, o un kofi desde otros países. Suscribite a mi blog aquí.