Novelas sobre la Navidad
En este post aprovechamos el nuevo dataset de la semana 52 del TidyTuesday 2025 y exploramos un corpus de novelas navideñas con herramientas de text mining en R, analizando la frecuencia de palabras, la polaridad de sentimientos, la correlación entre textos y los bígramos más frecuentes.
Esta semana exploramos novelas sobre la Navidad en el paquete gutenbergr. Hace mucho que no analizo datos de texto. De hecho, la última vez que hice algo con el libro Text Mining with R fue en enero de 2023, por lo que vamos a retomar de a poco. Como había llegado a revisar los primeros cuatro capítulos de ese libro, aquí voy a hacer cuatro preguntas generales para analizar los datos de esta semana, cada una correspondiente a cada uno de los primeros cuatro capítulos:
- ¿Qué novelas correlacionan entre sí en función de las palabras utilizadas?
- ¿Predominan las palabras con sentimientos negativos o positivos?
- ¿Cuáles son las palabras más frecuentes en estas novelas?
- ¿Cuáles son los bígramos (pares de palabras) más frecuentes en estas novelas?
Son todas preguntas muy generales porque, bueno, estamos empezando. Tengamos paciencia.
Preprocesamiento
En esta sección cargamos los datos y hacemos cualquier tipo de limpieza necesaria para trabajar con ellos.
# importamos los datos
tuesdata <- tidytuesdayR::tt_load('2025-12-30')## ---- Compiling #TidyTuesday Information for 2025-12-30 ----
## --- There are 3 files available ---
##
##
## ── Downloading files ───────────────────────────────────────────────────────────
##
## 1 of 3: "christmas_novel_authors.csv"
## 2 of 3: "christmas_novel_text.csv"
## 3 of 3: "christmas_novels.csv"# cargamos los df
christmas_novel_authors <- tuesdata$christmas_novel_authors
christmas_novel_text <- tuesdata$christmas_novel_text
christmas_novels <- tuesdata$christmas_novels
# cargamos librerías
library(tidyverse)## Warning: package 'tibble' was built under R version 4.4.1## Warning: package 'purrr' was built under R version 4.4.1## Warning: package 'stringr' was built under R version 4.4.1## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.6.0
## ✔ ggplot2 3.5.1 ✔ tibble 3.3.0
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.2.0
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(tidytext)## Warning: package 'tidytext' was built under R version 4.4.1Análisis exploratorio
Antes de empezar a responder las preguntas, podemos revisar cómo son los datos:
str(christmas_novels)## spc_tbl_ [42 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ gutenberg_id : num [1:42] 46 1902 2731 4384 8694 ...
## $ title : chr [1:42] "A Christmas Carol in Prose; Being a Ghost Story of Christmas" "The Old Peabody Pew: A Christmas Romance of a Country Church" "The Christmas Books of Mr. M.A. Titmarsh" "The Lost Word: A Christmas Legend of Long Ago" ...
## $ gutenberg_author_id: num [1:42] 37 266 313 362 102 ...
## - attr(*, "spec")=
## .. cols(
## .. gutenberg_id = col_double(),
## .. title = col_character(),
## .. gutenberg_author_id = col_double()
## .. )
## - attr(*, "problems")=<externalptr>str(christmas_novel_authors)## spc_tbl_ [35 × 6] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ gutenberg_author_id: num [1:35] 37 266 313 362 102 ...
## $ author : chr [1:35] "Dickens, Charles" "Wiggin, Kate Douglas Smith" "Thackeray, William Makepeace" "Van Dyke, Henry" ...
## $ birthdate : num [1:35] 1812 1856 1811 1852 1832 ...
## $ deathdate : num [1:35] 1870 1923 1863 1933 1888 ...
## $ wikipedia : chr [1:35] "https://en.wikipedia.org/wiki/Charles_Dickens" "https://en.wikipedia.org/wiki/Kate_Douglas_Wiggin" "https://en.wikipedia.org/wiki/William_Makepeace_Thackeray" "https://en.wikipedia.org/wiki/Henry_van_Dyke" ...
## $ aliases : chr [1:35] "Boz/Dickens, Charles John Huffam" "Riggs, Kate Douglas Smith Wiggin/Smith, Kate Douglas/Riggs, George Christopher, Mrs./Wiggin, Samuel Bradley, Mrs." "Titmarsh, Michael Angelo/Thackeray, W. M./Titmarsh, M. A./Thackeray, William M." "Dyke, Henry Van/Dyke, Henry Jackson Van/Dyke, Henry I. Van" ...
## - attr(*, "spec")=
## .. cols(
## .. gutenberg_author_id = col_double(),
## .. author = col_character(),
## .. birthdate = col_double(),
## .. deathdate = col_double(),
## .. wikipedia = col_character(),
## .. aliases = col_character()
## .. )
## - attr(*, "problems")=<externalptr>str(christmas_novel_text)## spc_tbl_ [114,134 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ gutenberg_id: num [1:114134] 46 46 46 46 46 46 46 46 46 46 ...
## $ text : chr [1:114134] "A CHRISTMAS CAROL" NA "IN PROSE" "BEING" ...
## - attr(*, "spec")=
## .. cols(
## .. gutenberg_id = col_double(),
## .. text = col_character()
## .. )
## - attr(*, "problems")=<externalptr>La base christmas_novels contiene el ID de las novelas, el título y el ID del autor. Muy probablemente esta base funcione como nexo con las demás. Los ID están en formato numérico, quizás más adelante convenga pasarlos a factor para que los trate como entidades separadas y no los sume ni haga promedios ni nada similar. La base christmas_novel_authors tiene el ID (debería ser el mismo que el de la base anterior) que representa a cada autor, su nombre completo, la fecha de nacimiento y muerte, su página de Wikipedia y el alias, en el caso que no publicara bajo su propio nombre. Y la base christmas_novel_text contiene el ID de la novela y el texto. Esta base es la más desordenada pero al mismo tiempo la más importante si queremos analizar el contenido.
Podemos empezar por preguntarnos cuántas novelas por autor(a) tenemos en nuestras bases:
christmas_novels %>%
group_by(gutenberg_author_id) %>% # agrupamos por autor(a)
summarise(cant = n()) %>% # contamos cuántas filas hay por grupo
arrange(desc(cant)) # organizamos la columna cant de mayor a menor## # A tibble: 35 × 2
## gutenberg_author_id cant
## <dbl> <int>
## 1 37 2
## 2 266 2
## 3 362 2
## 4 2334 2
## 5 3522 2
## 6 3796 2
## 7 6328 2
## 8 102 1
## 9 313 1
## 10 357 1
## # ℹ 25 more rowsTenemos 35 autores en nuestra base: solo de 7 de ellos tenemos dos novelas, del resto solo una. ¿Quiénes son? Para eso podemos hacer un join que consiste básicamente en unir dos bases a partir de una columna de referencia. En nuestro caso, vamos a partir de esta tabla de resumen y le vamos a sumar a la derecha los datos de los autores.
christmas_novels %>%
group_by(gutenberg_author_id) %>% # agrupamos por autor(a)
summarise(cant = n()) %>% # contamos cuántas filas hay por grupo
arrange(desc(cant)) %>% # organizamos la columna cant de mayor a menor
left_join(christmas_novel_authors, by = "gutenberg_author_id") ## # A tibble: 35 × 7
## gutenberg_author_id cant author birthdate deathdate wikipedia aliases
## <dbl> <int> <chr> <dbl> <dbl> <chr> <chr>
## 1 37 2 Dickens, Cha… 1812 1870 https://… Boz/Di…
## 2 266 2 Wiggin, Kate… 1856 1923 https://… Riggs,…
## 3 362 2 Van Dyke, He… 1852 1933 https://… Dyke, …
## 4 2334 2 Hughes, Rupe… 1872 1956 https://… <NA>
## 5 3522 2 Williamson, … 1859 1920 https://… Willia…
## 6 3796 2 Williamson, … 1869 1933 https://… Willia…
## 7 6328 2 Dalrymple, L… 1884 1968 https://… Dalrym…
## 8 102 1 Alcott, Loui… 1832 1888 https://… Barnar…
## 9 313 1 Thackeray, W… 1811 1863 https://… Titmar…
## 10 357 1 Mitchell, S.… 1829 1914 https://… Mitche…
## # ℹ 25 more rowsEl Proyecto Gutenberg tiene como objetivo la preservación digital de los libros, especialmente aquellos que ya no cuentan con derechos de autor. Esto ya nos da una idea de las fechas aproximadas de muerte de los autores; sin embargo, podemos hacer un gráfico lollipop para observar la coexistencia de estos autores.
# convertimos los autores en factor
christmas_novel_authors$gutenberg_author_id <- as.factor(christmas_novel_authors$gutenberg_author_id)
# gráfico
ggplot(christmas_novel_authors)+
# para crear las líneas
geom_segment(aes(y = birthdate, yend = deathdate,
x = gutenberg_author_id, xend = gutenberg_author_id),
color = "grey")+
# para crear el punto de nacimiento
geom_point(aes(x = gutenberg_author_id, y = birthdate), color = "green")+
# para crear el punto de muerte
geom_point(aes(x = gutenberg_author_id, y = deathdate), color = "red")+
# rotación 90 grados
coord_flip()+
# quito los nombres de los ejes y agrego un título
labs(x = "",y = "",
title = "Año de nacimiento y muerte de los autores analizados")+
# quito los nombres de autores en el eje y
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank())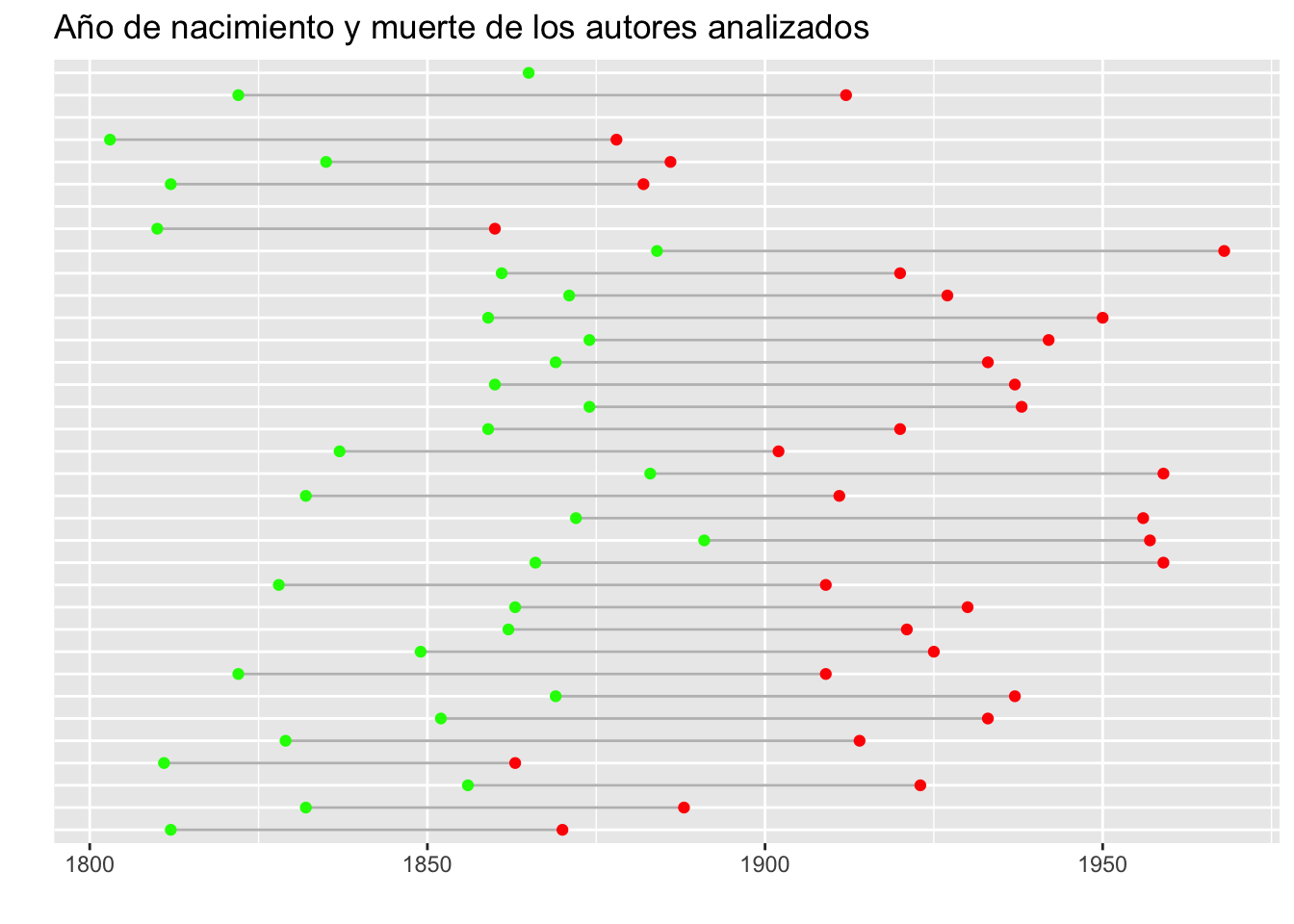
No es el gráfico más lindo del mundo, pero sirve para tener una idea del rango temporal de las novelas que vamos a analizar. Vemos por ejemplo que la amplia mayoría, salvo cinco excepciones, murieron antes de 1950, y ninguno llega a los 2000. Sería interesante incorporar al gráfico, por ejemplo con un punto negro, el momento en el que escribieron la novela que vamos a analizar, pero lamentablemente esa información no está en las bases. Se podría buscar, sí, pero por ahora me voy a limitar a lo que tenemos.
Empezamos con el análisis del texto de las novelas. Para trabajar con texto, el formato tidytext (“texto limpio u ordenado”), relacionado con el ecosistema tidydata, propone que cada observación sea un token, que es una unidad significativa de texto. Este token puede ser una palabra, un conjunto de palabras, una línea, un párrafo, lo que necesitemos. En general, la mayoría de los análisis usan la palabra, porque desde ese orden se puede luego aumentar y combinar en el caso de ser necesario. Vamos hacia ello.
novels <- christmas_novel_text %>%
# quitamos las observaciones con NA
filter(!is.na(text)) %>%
# agrupamos por libro
group_by(gutenberg_id) %>%
# creamos dos columnas nuevas: número de línea y capítulo
mutate(nro_linea = row_number(),
capitulo = cumsum(str_detect(text,
regex("^(chapter|stave)\\s+[divxlc]+",
ignore_case = TRUE)))) %>%
ungroup()Del bloque de código anterior, quizás lo que está dentro del mutate() requiere un poco más de atención. Creamos dos columnas nuevas: la primera, nro_linea se construye a partir del número de fila con la función row_number() (es decir, por cada agrupación en libro, cuenta 1, 2, 3…), para no perder el orden en que aparecen las palabras. La segunda columna, capitulo, se construye con la función cumsum() que hace una suma acumulativa (empezando por 0) a partir de una condición lógica. Si esa condición se cumple (TRUE), entonces se suma 1, de lo contrario se mantiene en la cantidad anterior. En este caso, la condición es la detección de una cadena con la función str_detect() que toma como primer argumento la columna donde buscar (text) y como segundo argumento el patrón a buscar, que aquí es una expresión regular que significa: “la celda empieza con la palabra chapter o stave, luego puede tener una serie de espacios, y luego alguna de las letras divxlc”. De esta forma, cada vez que encuentra una fila que cumple con esa función, dentro de cada libro, la función cumsum() sumará +1, con lo cual tendremos una columna que diferencia entre capítulos al interior de cada libro.
Una vez que nuestra base tiene indicados los libros y los capítulos, podemos desarmar las frases para tener una sola palabra por cada fila. Esto se hace con la función unnest_tokens() del paquete tidytext que cargamos anteriormente.
tidy_novels <- novels %>%
unnest_tokens(word, text)Algo que suelen hacer quienes hacen procesamiento del lenguaje natural es eliminar las “palabras vacías” [stop words], que suelen ser palabras de clase cerrada como preposiciones o artículos, pero también otras como pronombres o adverbios. A decir verdad, como lingüista me genera mucho ruido este paso, porque no parece tener, al menos hasta donde sé, una teoría del funcionamiento del lenguaje detrás. Por el momento, vamos a hacer oídos sordos a ese ruido y eliminar las palabras vacías de nuestra base. Esto lo hacemos con un anti_join() que genera el efecto opuesto del join que hicimos anteriormente: elimina de la primera base aquellos elementos que también están en la segunda base que inserto.
data("stop_words")
tidy_novels <- tidy_novels %>%
anti_join(stop_words)Ahora podemos contar cuáles son las palabras más frecuentes en cada uno de los libros y hacer un gráfico:
tidy_novels %>%
count(word, sort = T) %>%
filter(n > 600) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(n, word)) +
geom_col() +
labs(y = NULL)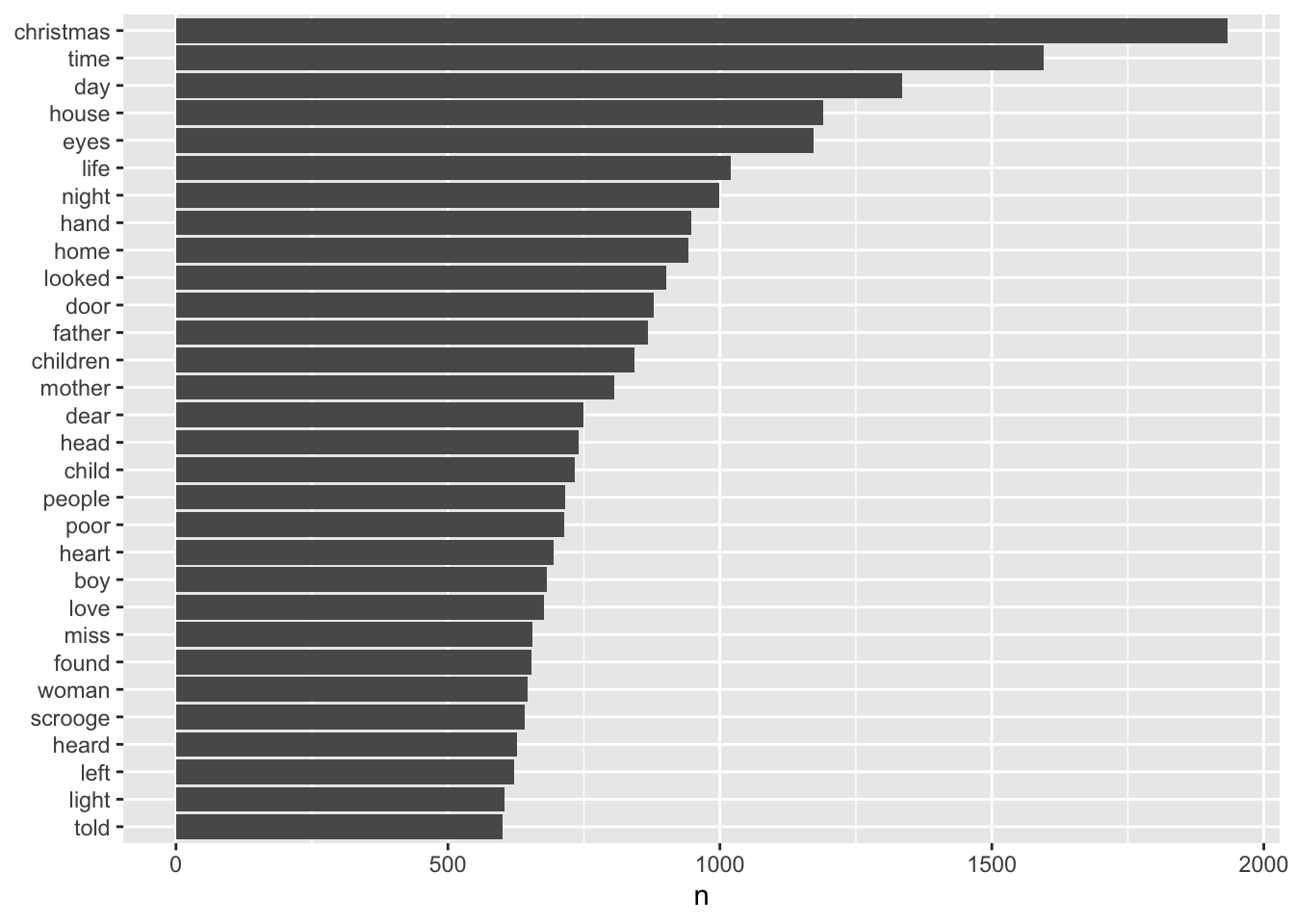
Que “christmas” (navidad) sea la palabra más frecuente no debería sorprendernos, ya que el dataset contiene justamente libros sobre la Navidad. Esto puede parecer una obviedad, pero a veces ocurre que nos enfrascamos mucho en un análisis y nos olvidamos por ejemplo los criterios utilizados en la selección o recolección de datos. La segunda y la tercera palabra (“time”, tiempo y “day”, día) posiblemente estén relacionadas también con la Navidad, ya que “Christmas day” y “Christmas time” funcionan como collocations.
De hecho, podemos explorar esta hipótesis cambiando nuestra unidad de análisis: en lugar de tomar la palabra aislada, tomamos una serie de palabras consecutivas. Esta combinación se denomina n-grams y es una opción dentro de la función unnest_tokens(). Dos palabras consecutivas conforman un bígramo.
novels_bigramos <- novels |>
unnest_tokens(bigram, text, token = "ngrams", n = 2) |>
filter(!is.na(bigram)) |>
count(bigram, sort = TRUE) |>
view()Observamos que los bígramos más frecuentes son los que tienen las stop-words tales como preposiciones o artículos. Para filtrar aquellos bígramos donde haya una de estas palabras, primero tenemos que separar los bígrmaos con la función separate(), que convertirá cada bígramo en dos columnas, luego filtramos aquellas filas donde alguna de las dos palabras sea una stop-word y después volvemos a contar.
bigramos_nuevos <- novels_bigramos |>
separate(bigram, # columna a separar
into = c("word1", "word2"), # columnas nuevas
sep = " ") |> # separador a identificar en la columna original
filter(!word1 %in% stop_words$word) |>
filter(!word2 %in% stop_words$word) |>
count(word1, word2, sort = TRUE)Ahora que ya tenemos nuestros bígramos, podemos buscar aquellos donde la primera palabra sea christmas:
bigramos_nuevos |>
filter(word1 == "christmas") |> view()En efecto, “christmas day” aparece 100 veces y “christmas time” 22 veces, lo cual colabora en nuestra hipótesis. Pero también aparecen otras combinaciones interesantes como “christmas eve”, que introduce un matiz temporal distinto (la víspera), o incluso algunas menos esperables que podrían remitir a usos más figurados o narrativos del término. Es decir, confirmamos que ciertas combinaciones son frecuentes y empezamos a ver cómo se construye semánticamente la Navidad en estos textos: como un momento (time), un día específico (day) o incluso un evento cargado de expectativas (eve).
Hasta acá, el recorrido fue deliberadamente introductorio. Partimos de preguntas amplias, trabajamos con unidades simples como palabras y bígramos, y aplicamos operaciones bastante estándar dentro del ecosistema de tidytext. Sin embargo, incluso con este nivel de análisis, ya se empiezan a delinear algunos patrones: la fuerte centralidad de ciertos núcleos léxicos, la recurrencia de combinaciones estables y la importancia de no perder de vista el contexto de producción de los datos (en este caso, novelas explícitamente navideñas y mayormente previas a mediados del siglo XX).
En futuras iteraciones, sería interesante avanzar hacia análisis más complejos: incorporar medidas de asociación entre palabras (como tf-idf o correlaciones), explorar sentimientos con distintos léxicos o incluso modelar tópicos para identificar temas recurrentes más allá de la intuición inicial. Por ahora, lo importante era volver a poner en marcha la maquinaria y recuperar familiaridad con las herramientas.
Como suele pasar en estos casos, más que respuestas definitivas, lo que nos llevamos son nuevas preguntas —y un corpus listo para seguir siendo explorado.
Macarena Quiroga
Lingüista/Becaria doctoral
Investigo la adquisición del lenguaje. Estudio estadística y ciencia de datos con R/Rstudio. Si te gusta lo que hago, podés invitarme un cafecito desde Argentina, o un kofi desde otros países. Suscribite a mi blog aquí.