¡Auxilio! ¿Cómo hago gráficos en R?
En este post veremos cómo visualizar datos de forma simple en R y RStudio con la función plot().
 Imagen hecha por mí con el paquete {aRtsy}
Imagen hecha por mí con el paquete {aRtsy}Bienvenidas y bienvenidos a la tercera publicación de la saga ¡Auxilio! Tengo datos cuantitativos, ¿y ahora qué hago? dirigida a todas aquellas personas que deban empezar a realizar análisis estadísticos y nunca hayan hecho más nada que una grilla de horarios en Excel. En el primer post vimos cómo instalar R y RStudio, cómo cargar los datos y cómo inspeccionar a grandes rasgos nuestra tabla. Luego, en el segundo post vimos cómo calcular la media, la mediana y la moda en R, cómo hacer esos cálculos diferenciando entre grupos y qué hacer si tengo datos faltantes.
En este post vamos a empezar a ver cómo realizar gráficos con R. Como mencioné en el post anterior, en esta saga vamos a intentar utilizar solamente funciones de R base, sin acudir a otros paquetes. Existen muchos paquetes que proveen herramientas poderosísimas de visualización (hola, ggplot2), pero el objetivo de estos posts es intentar resolverte la vida, no complicártela. Tal vez no logres los gráficos más lindos y rimbombantes del universo, pero sí vas a tener visualizaciones claras y precisas para entender un poco más tus datos, para compartir con tu equipo y también para publicar en revistas científicas. ¡Empecemos!
Primer paso: los datos
Como recordarás de los posts previos, lo primero que tenemos que hacer es cargar los datos. En este caso estamos trabajando con una tabla de datos de pingüinos que nos aporta el paquete datos. Si nunca lo instalaste, corré estos comandos; si ya lo instalaste, solamente el segundo y el tercero (recordatorio: para ejecutar un comando, ubicá el cursor en esa línea y apretá control+enter o hacé click en Run en la esquina superior derecha del panel del script; si no recordás que es todo esto, revisá el primer post).
install.packages("datos")
library(datos)
pinguinos <- pinguinosEn el segundo post habíamos calculado tres medidas importantes de estadística descriptiva básica: la media, la mediana y la moda. Estos tres valores nos servían para empezar a entender cómo se comportaban los datos, tanto en términos generales (por ejemplo, el largo del pico) como en subgrupos (diferencias por sexo del largo del pico). Presentar la información de forma gráfica nos ayuda a entender las diferencias o similitudes.
Segundo paso: visualizaciones automáticas con plot()
Una de las funciones básicas que permite visualizar los datos es plot(), que sin más vueltas grafica los datos que le pasemos como argumento en función del tipo de dato que sea. La ventaja es que no necesitamos pensar mucho: elegimos la variable que queremos ver y la función decidirá por sí misma qué gráfico es más conveniente. Por ejemplo, si me interesa la isla de proveniencia de los pingüinos, puedo ejecutar el siguiente comando:
plot(pinguinos$isla)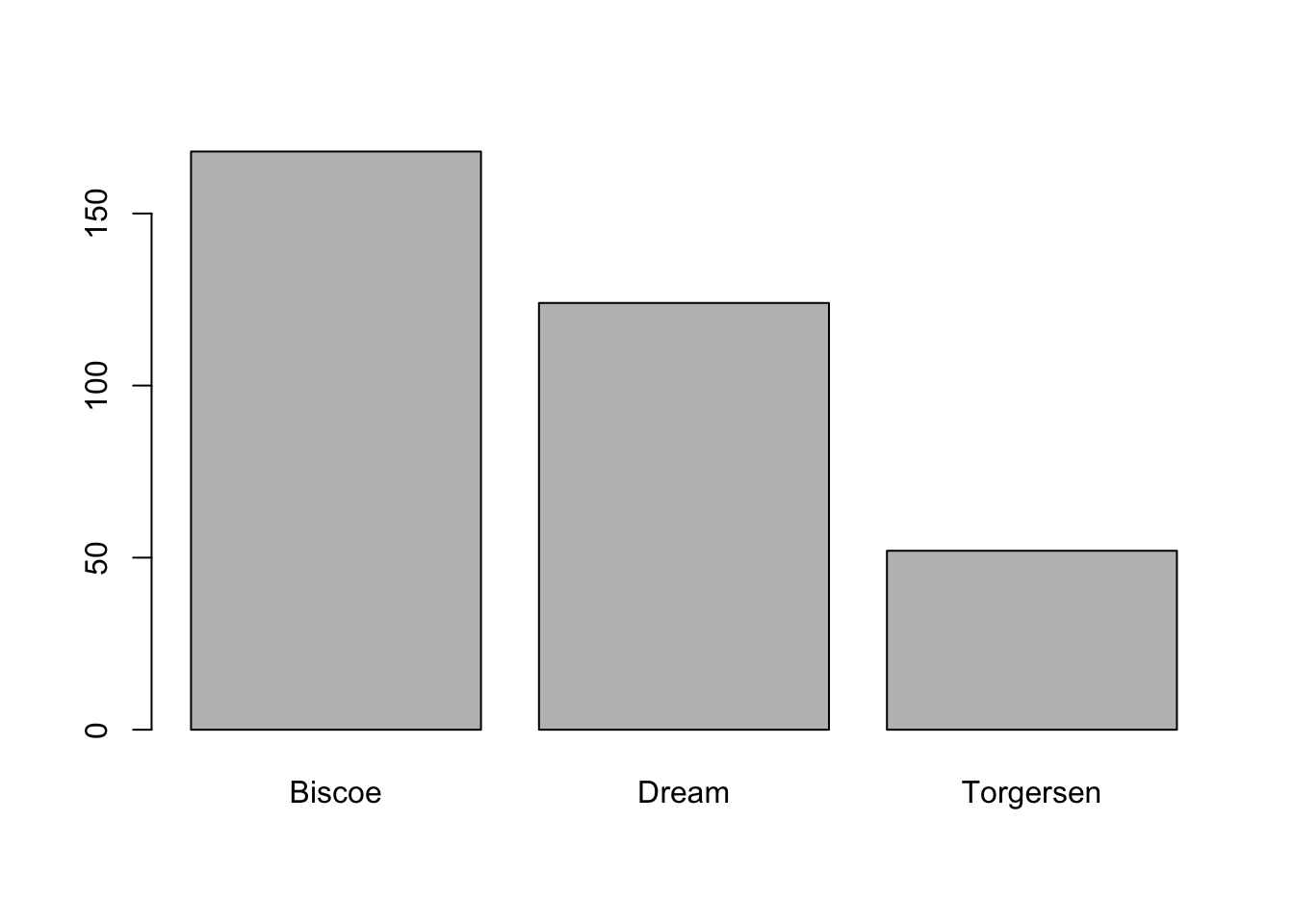
# el signo $ se usa para seleccionar una columna dentro de la tabla o dataframeComo la variable isla es categórica (es decir, los valores que puede tomar son nombres o clasificaciones que diferencian entre grupos), obtuvimos un gráfico de barras que cuenta cantidades de pingüinos por islas. En el eje x (horizontal) tenemos los nombres de las islas y en el eje y (vertical) tenemos la cantidad de pingüinitos (u observaciones) que hay en cada una.
En cambio, si pasamos como argumento una variable numérica, como el largo del pico, vemos que el resultado es muy distinto:
plot(pinguinos$largo_pico_mm)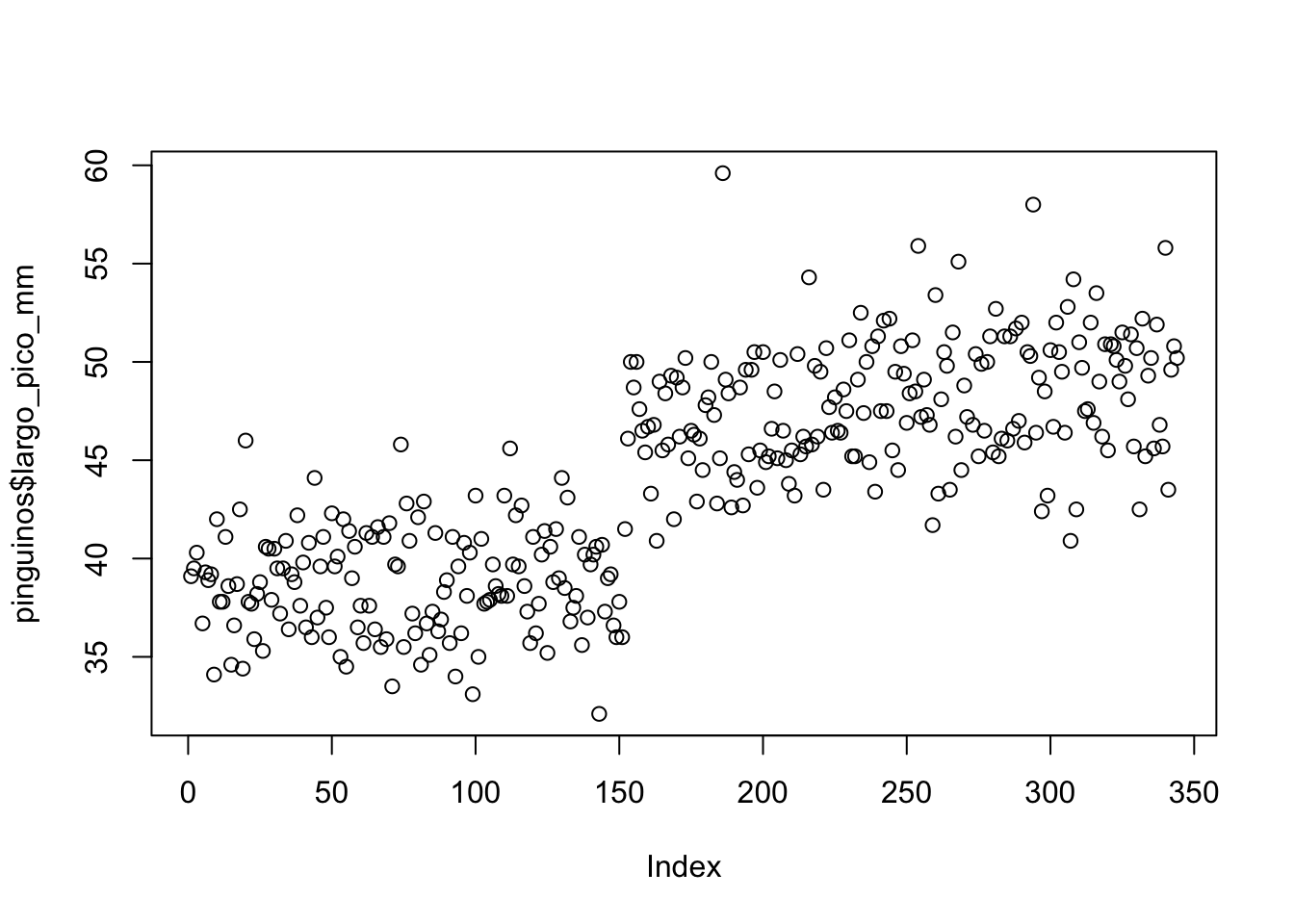
Esto se llama diagrama de dispersión y es un tipo de gráfico que muestra la correlación entre dos variables numéricas. Me imagino que estarás pensando: ¿cómo dos variables, si yo le pasé una sola? y tenés razón, pero mirá lo que aparece en el eje x: Index. El valor de index (o índice, en español) hace referencia a la cantidad de observaciones. Entonces, cada puntito del gráfico es un pingüino. Este gráfico nos muestra que parecería haber dos grandes grupos: uno con un pico más bien corto (el de la izquierda) y otro con un pico más bien largo (el de la derecha). Sin embargo, esto no parece ser el gráfico más claro o al menos más útil, porque no sabemos en qué orden están los datos (es decir, qué diferencias hay entre el 1 y el 350). Pero como un primer paso, está bien.
El diagrama de dispersión tiene más sentido cuando efectivamente se eligen dos variables numéricas reales, como por ejemplo el largo y el alto del pico.
plot(pinguinos$largo_pico_mm, pinguinos$alto_pico_mm)
# los argumentos dentro de una función siempre se separan con una comaEste gráfico, si bien parece no ser tan claro como el anterior, tiene más sentido desde la teoría: cada punto marca la correlación que hay entre el largo y el alto del pico de los pingüinos. De todos modos, se empieza a notar que hay grupos, es decir, se ven ciertas nubes de punto que parecen agruparse en función de alguna subdivisión que todavía no sabemos. Lo que podemos hacer es pensar: ¿qué variable podría separar estas nubes? Hay tres opciones categóricas: el sexo y la especie de los pingüinos, y la isla de procedencia. Entonces, si queremos ver cómo se relacionan estas variables, podemos hacer que cada punto tenga un color distinto según, por ejemplo, el sexo:
plot(pinguinos$largo_pico_mm, pinguinos$alto_pico_mm, col = pinguinos$sexo)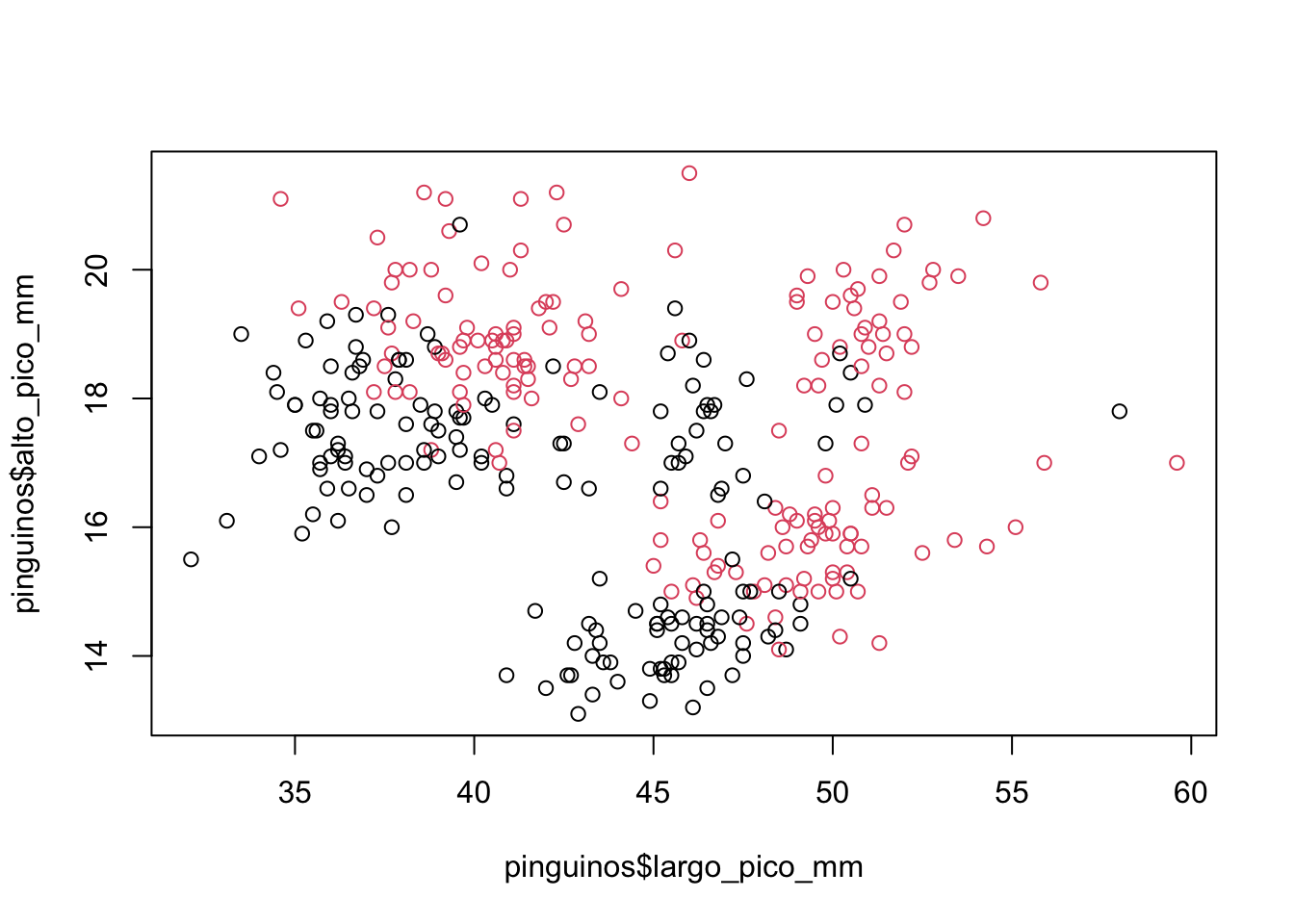
El argumento col especifica la variable de agrupación según la cual se va a colorear cada uno de los puntos. Tené presente que esa variable tiene que ser categórica, no numérica, para poder permitir la división en grupos. Finalmente, fijate que los tres argumentos que aparecen en la función siguen la misma sintaxis: tabla$columna.
Vemos entonces que hay cierto patrón en la relación entre el alto y el largo del pico, pero así tal como está el gráfico no sabemos qué puntos son los pingüinos macho y cuáles las hembras. La tabla de referencia en R se llama legend y se le puede agregar a un gráfico con una función extra. Ya que estamos, vamos a especificar dentro de la función que venimos usando nombres un poco más amigables para los ejes, llamados labels:
plot(pinguinos$largo_pico_mm, pinguinos$alto_pico_mm,
col = pinguinos$sexo,
xlab = "Largo del pico (mm)",
ylab = "Alto del pico (mm)")
legend("topright", legend = unique(pinguinos$sexo),
col = unique(pinguinos$sexo), pch = 19)
Tené en cuenta que son dos funciones distintas (plot() y legend()), entonces tenés que correr cada una por separado. La segunda se agrega sobre el gráfico anterior, por lo tanto si querés hacer un cambio en el gráfico te conviene correrlo todo de nuevo.
Ahora, miremos con más detalle esa segunda función. El primer argumento es la posición del cuadro y puede tomar los siguientes valores: “bottomright” (abajo a la derecha), “bottom” (abajo al centro), “bottomleft” (abajo a la izquierda), “left” (izquierda al centro), “topleft” (arriba a la izquierda), “top” (arriba al centro), “topright” (arriba a la derecha), “right” (derecha al centro) and “center” (centro del cuadrado).
El segundo argumento especifica el texto del cuadro de referencia (es decir, cada ítem). Acá tenés dos opciones: la que hicimos acá fue especificar la variable de agrupación; le tuvimos que especificar que tome los valores únicos de esa variable con la función unique(), porque sino va a hacer una lista con el valor de cada uno de los puntos (podés probar qué pasaría si sacás esa parte). La otra opción es especificar a mano: legend = c("macho", "hembra"). Como tenemos dos valores, los tenemos que concatenar y eso se hace con la función c(), que lo que hace es marcar un conjunto de elementos. Esta alternativa es buena si por algún motivo tenés que cambiar el texto (suponete que en la columna tuvieras M y H pero igual querés las palabras “macho” y “hembra” en el gráfico); la desventaja es que si ponés los nombres en el orden inverso al que están codificados, podés invertir los colores. Para chequear el orden de los grupos, podés ejecutar el siguiente comando en la consola: levels(pinguinos$sexo) y te va a indicar los niveles de esa variable.
El tercer argumento es similar al anterior, pero para definir los colores del gráfico. Lo que hicimos nosotros fue decirle: “usá un color distinto para cada uno de los valores de esta variable”, pero podríamos haber indicado dos colores, por ejemplo cols = c("blue", "green") (la lista de colores de R base la encontrás en este link).
Finalmente, el argumento pch o plotting character indica el símbolo a utilizar. R base ofrece varios símbolos distintos:

En general, el símbolo más usado es el 19, el círculo; en los casos en los que se necesita marcar otras diferencias, se puede usar el triángulo (17), pero son casos raros.
Hay más detalles visuales que se pueden agregar, como un título o un pie de imagen; podés leer más sobre esto en la documentación oficial.
Tercer paso: guardar las imágenes
Una vez que te sientas conforme con la imagen que lograste, tenés varias alternativas para descargarla. La más fácil es ir al panel de abajo a la derecha y hacer click en Export, luego Save as image y listo. También podés hacer copypaste de la imagen en el documento que necesites.
Sin embargo, a veces las revistas son un poco quisquillosas con las imágenes y piden que tengan determinada calidad o determinado tamaño. En esos casos, podés usar la función png() o jpg() con las especificaciones que necesites.
png("prueba2.png", res = 150, width = 1000, height = 500, units = "px")
plot(pinguinos$largo_pico_mm, pinguinos$alto_pico_mm,
col = pinguinos$sexo,
xlab = "Largo del pico (mm)",
ylab = "Alto del pico (mm)")
legend("topright", legend = unique(pinguinos$sexo),
col = unique(pinguinos$sexo), pch = 19)
dev.off()El orden es el siguiente: primero se ejecuta la función que indica las especificaciones del gráfico que queremos hacer, luego ejecutamos la o las funciones del gráfico en sí (en este caso tenemos dos: el gráfico y el cuadro de referencia superpuesto) y finalmente debemos cerrar el proceso con dev.off(), una función que le indica a R que el procesador gráfico ya puede terminar.
Cierre
En este post vimos un primer acercamiento a cómo realizar gráficos en R. Nos concentramos en una sola función, plot(), que si bien no es la más visualmente atractiva, tiene mucho para dar. En el próximo post vamos a ver otros tipos de gráficos distintos que se ajustan a otras situaciones.
Como siempre, recordá que podés suscribirte a mi blog para no perderte ninguna actualización, y si te quedó alguna consulta no dudes en contactarme. Y, si te gusta lo que hago, podés invitarme un cafecito desde Argentina o un kofi.
Macarena Quiroga
Lingüista/Becaria doctoral
Investigo la adquisición del lenguaje. Estudio estadística y ciencia de datos con R/Rstudio. Si te gusta lo que hago, podés invitarme un cafecito desde Argentina, o un kofi desde otros países. Suscribite a mi blog aquí.