Cómo hacer correlaciones en R
En este post vamos a ver qué son y cómo hacer correlaciones en R.
Introducción: ¿qué es una correlación?
Una correlación es una asociación lineal entre dos variables: básicamente, nos preguntamos si el valor que toma la variable A aumenta o disminuye en función de la variable B, y viceversa. Esta última palabra es fundamental: las correlaciones (a diferencia de otras asociaciones lineales, como por ejemplo la regresión) no apunta a buscar un impacto o efecto de una variable sobre otra, sino simplemente la asociación entre ambas variables.
Un ejemplo común de correlaciones es entre el peso y la altura de las personas: mientras más altas sean las personas, más suelen pesar, y viceversa. Ese es el caso de una correlación positiva: las dos variables aumentan o disminuyen de forma conjunta. Sin embargo, las correlaciones pueden tener el sentido contrario: por ejemplo, a mayor edad de los sujetos, menor tiempo necesario para leer una palabra. Ese sería el caso de una correlación negativa: cuando una variable aumenta, la otra disminuye. Esto es lo que se denomina el sentido de la correlación. Además del sentido, se suele analizar también la fuerza de la correlación: débil, moderada o fuerte.
El gráfico por excelencia que permite encontrar correlaciones es el diagrama de dispersión (scatterplot, en inglés), y vimos una forma sencilla de realizarlos en un post anterior. Con el ya conocido y querido conjunto de datos de pingüinos:
# install.packages("datos")
library(datos)
pinguinos <- datos::pinguinos
plot(pinguinos$largo_pico_mm, pinguinos$largo_aleta_mm)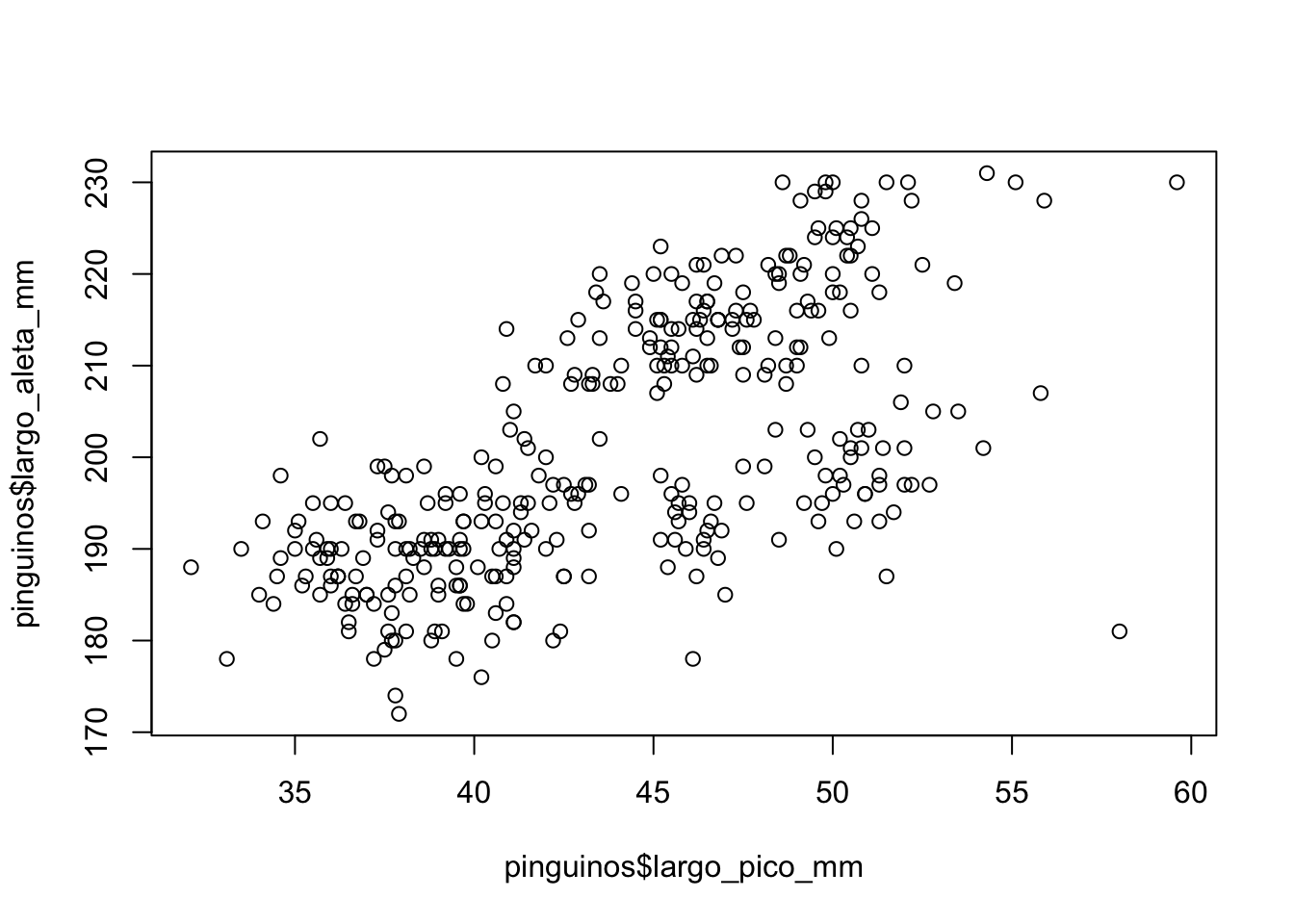
Ya visualmente podemos empezar a sospechar la presencia de una correlación: la inclinación ascendente de los puntos parece sugerir que aquellos pingüinos con aletas más largas también tienen picos más largos. Por suerte, no tenemos que depender exclusivamente de nuestra percepción visual para analizar las correlaciones: podemos utilizar la correlación de Pearson.
La correlación de Pearson
Existen varios métodos para testear una correlación, pero el coeficiente de correlación de Pearson es una de las más usadas porque, a diferencia de la covarianza, por ejemplo, está corregida por el producto del desvío estándar de las variables, toma valores entre 0 y 1, y su coeficiente es independiente de la unidad de medida de las variables. Esto lo vuelve más fácilmente interpretable.
Por suerte, tenemos disponibles muchas funciones para testear correlaciones. La más básica es la función cor() de R base, que toma como argumentos las dos columnas o variables que queremos correlacionar. Recordá, como vimos en un post anterior, que usamos el signo $ para seleccionar la variable dentro del dataframe.
cor(pinguinos$largo_pico_mm, pinguinos$largo_aleta_mm)## [1] NABueno, empezamos mal. ¿Por qué el resultado es NA, es decir, not available? Hay muchas explicaciones a este fenómeno, pero la más importante o la primera que tendríamos que testear es justamente la presenta de valores faltantes (NA) en las columnas que queremos analizar. Por suerte, la función cor() tiene un argumento optativo llamado use = que permite especificar qué elementos queremos usar para aplicar esa función.
Si miramos la documentación, ejecutando ?cor en la consola, vamos a ver que las opciones son everything si queremos usar todas las variables y, en el caso de que haya algún valor ausente, el resultado será NA; luego, existe la opción all.obs que es conceptualmente similar a la anterior, con la diferencia de que ante la presencia de un valor faltante arrojará un error en la consola; la opción complete.obs solamente utilizará las observaciones que no tengan valores faltantes y arrojará un error si no hay observaciones completas; na.or.complete es equivalente pero ante la falta de observaciones completas arrojará NA como resultado, y finalmente pairwise.complete.obs es una versión más conservadora de complete.obs porque solamente utiliza las filas que estén absolutamente completas. En nuestro caso, la diferencia entre complete.obs y pairwise.complete.obs no es muy evidente porque estamos seleccionando solo dos columnas, pero si nos interesara analizar las correlaciones entre varias columnas de un dataframe, sería más relevante.
Entonces, completamos nuestra función:
cor(pinguinos$largo_pico_mm, pinguinos$largo_aleta_mm, use = "complete.obs")## [1] 0.6561813Bien, ahora obtuvimos un resultado: 0.656. Podemos ver el sentido de la correlación: al ser un número positivo, asumimos que quienes tienen picos más largos también tienen aletas más largas; vemos también la fuerza de la correlación, que es moderada/fuerte1. Sin embargo, habrán notado que esta función solamente arroja el coeficiente de Pearson, pero nada más. Si necesitamos, por ejemplo, una prueba de significatividad que arroje un valor p, podemos usar la siguiente función:
cor.test(pinguinos$largo_pico_mm, pinguinos$largo_aleta_mm)##
## Pearson's product-moment correlation
##
## data: pinguinos$largo_pico_mm and pinguinos$largo_aleta_mm
## t = 16.034, df = 340, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.5912769 0.7126403
## sample estimates:
## cor
## 0.6561813Acá tenemos el mismo coeficiente de correlación, pero además nos brinda otros datos estadísticos relevantes, como los grados de libertad, el p-valor y el intervalo de confianza. Con estos datos, ya podemos reportar los resultados.
Un momento… ¿podemos? Si leyeron el post sobre comparación entre grupos o el post sobre ANOVA, recordarán que la distribución de los datos define si podemos usar pruebas paramétricas, en el caso de que sigan una distribución normal, o no paramétricas. Y en este caso no testeamos ni la normalidad ni la homogeneidad de la varianza (es decir, la homoscedasticidad).
Primero tenemos que testear la normalidad, para lo cual usamos la función shapiro.test. En este caso, necesitamos testar ambas variables por separado, entonces para escribir una sola línea de código vamos a usar la función lapply() que justamente permite aplicar una misma función a varios elementos (ya habíamos usado una función similar, tapply(), en el segundo post sobre gráficos). La sintaxis es la siguiente: el primer argumento es el objeto sobre el cual queremos aplicar la función (en este caso, dos columnas específicas del dataframe), y luego la función específica, sin paréntesis.
# normalidad
lapply(pinguinos[c("largo_pico_mm", "largo_aleta_mm")],
FUN = shapiro.test)## $largo_pico_mm
##
## Shapiro-Wilk normality test
##
## data: X[[i]]
## W = 0.97485, p-value = 1.12e-05
##
##
## $largo_aleta_mm
##
## Shapiro-Wilk normality test
##
## data: X[[i]]
## W = 0.95155, p-value = 3.54e-09Notarán que en la consola se imprimen dos bloques de resultados, uno para cada columna. Si guardaran el resultado en un objeto, verían que en la consola este objeto es una lista, un tipo de elemento que es un conjunto de datos que pueden ser de distintas naturalezas (es decir, una lista puede contener por ejemplo números, letras, otras listas, dataframes, etc). Les prometo que de acá a 2035 les voy a hacer un post sobre los tipos de datos y tipos de estructuras que se utilizan en R.
En fin, lo importante de todo esto es que ninguna de las dos variables tiene una distribución normal, porque el p-valor es menor a 0.052. Esto significa que no deberíamos haber usado la correlación de Pearson (oops). En este caso, como estamos calculando correlaciones y no comparaciones entre grupos, no necesitamos testear homogeneidad de varianzas, así que ya estamos listos para adentrarnos en el mundo de las pruebas no paramétricas: la correlación de Spearman.
La correlación de Spearman
Pueden leer un poco más sobre la correlación de Spearman en su entrada de Wikipedia, pero básicamente es una prueba no paramétrica basada en rangos, al igual que la U de Mann-Whitney. Su interpretación es idéntica a la correlación de Spearman, y para calcularla solo tenemos que especificarlo como argumento en la sintaxis de la función que ya usamos:
cor.test(pinguinos$largo_pico_mm, pinguinos$largo_aleta_mm,
method = "spearman",
exact = FALSE)##
## Spearman's rank correlation rho
##
## data: pinguinos$largo_pico_mm and pinguinos$largo_aleta_mm
## S = 2181594, p-value < 2.2e-16
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.6727719El p-valor es significativo y el valor del coeficiente \(\rho\) es de 0.67, lo cual indica que es una correlación moderada-fuerte. ¡Genial! Fíjense que la consola también arrojó una advertencia, cannot compute exact p-values with ties: esto tiene que ver con la forma de manejar los rangos, pero no debería preocuparnos (aunque, si te interesa, en StackOverflow podés leer este post y este otro sobre el tema).
Para terminar: ¿cómo se reporta una correlación?
El análisis de correlaciones indicó la presencia de una correlación moderada-fuerte entre el largo del pico y el largo de las aletas de los pingüinos (r = 0.67, p < 0.001).
Cierre
En este post vimos cómo calcular correlaciones en R, tanto con la prueba paramétrica de Pearson como con su versión no paramétrica de Spearman. Recordamos también cómo se testea el supuesto de normalidad y aprendimos una función nueva de R base.
Como siempre, recordá que podés suscribirte a mi blog para no perderte ninguna actualización, y si tenés alguna pregunta, no dudes en contactarme. Y si te gusta lo que hago, puedes invitarme a tomar un cafecito desde Argentina o un kofi desde otros países.
Los intervalos numéricos para interpretar una correlación como débil, moderada o fuerte no son absolutos. En general, en psicología y en ciencias humanas se suele considerar que una correlación de menos de 0.4 es débil, entre 0.4 y 0.6 es moderada, y mayor a 0.6 es fuerte. En cambio, en áreas de ciencias exactas puede considerarse moderada recién en 0.5 y fuerte en 0.8. Como decimos en Argentina, cada maestro con su librito.↩︎
Respecto al tema de las distribuciones, les quiero recomendar este post sobre tipos de distribuciones de probabilidad que me pareció muy claro y didáctico (en inglés, sorry).↩︎
Macarena Quiroga
Lingüista/Becaria doctoral
Investigo la adquisición del lenguaje. Estudio estadística y ciencia de datos con R/Rstudio. Si te gusta lo que hago, podés invitarme un cafecito desde Argentina, o un kofi desde otros países. Suscribite a mi blog aquí.